Note
Go to the end to download the full example code.
Surrogate Models¶
Some industrial applications require modeling complex processes that can result either in highly nonlinear functions or functions defined by a simulation process. In those contexts, optimization solvers often struggle. The reason may be that relaxations of the nonlinear functions are not good enough to make the solver prove an acceptable bound in a reasonable amount of time. Another issue may be that the solver is not able to represent the functions.
An approach that has been proposed in the literature is to approximate the problematic nonlinear functions via neural networks with ReLU activation and use MIP technology to solve the constructed approximation (see e.g. Heneao Maravelias 2011, Schweitdmann et.al. 2022). This use of neural networks can be motivated by their ability to provide a universal approximation (see e.g. Lu et.al. 2017). This use of ML models to replace complex processes is often referred to as surrogate models.
In the following example, we approximate a nonlinear function via
Scikit-learn MLPRegressor and then solve an optimization problem
that uses the approximation of the nonlinear function with Gurobi.
The purpose of this example is solely illustrative and doesn’t relate to any particular application.
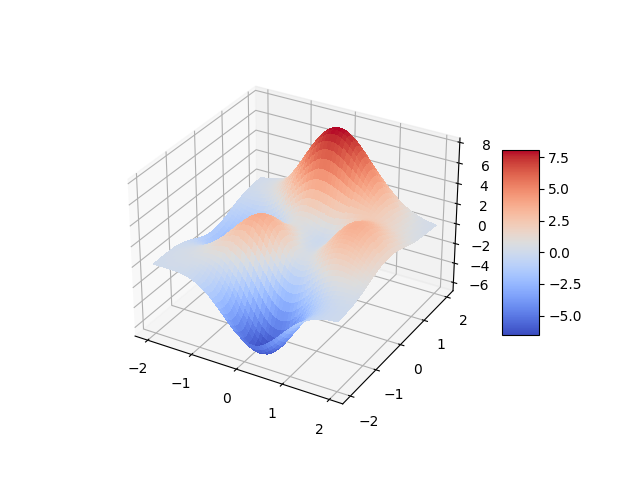
The function we approximate is the 2D peaks function.
The function is given as
In this example, we want to find the minimum of \(f\) over the interval \([-2, 2]^2\):
The global minimum of this problem can be found numerically to have value \(-6.55113\) at the point \((0.2283, -1.6256)\).
Here to find this minimum of \(f\), we approximate \(f(x)\) through a neural network function \(g(x)\) to obtain a MIP and solve
First import the necessary packages. Before applying the neural network,
we do a preprocessing to extract polynomial features of degree 2.
Hopefully this will help us to approximate the smooth function. Besides,
gurobipy, numpy and the appropriate sklearn objects, we also
use matplotlib to plot the function, and its approximation.
import gurobipy as gp
import numpy as np
from gurobipy import GRB
from matplotlib import cm
from matplotlib import pyplot as plt
from sklearn import metrics
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from gurobi_ml import add_predictor_constr
Define the nonlinear function of interest¶
We define the 2D peak function as a python function.
def peak2d(x1, x2):
return (
3 * (1 - x1) ** 2.0 * np.exp(-(x1**2) - (x2 + 1) ** 2)
- 10 * (x1 / 5 - x1**3 - x2**5) * np.exp(-(x1**2) - x2**2)
- 1 / 3 * np.exp(-((x1 + 1) ** 2) - x2**2)
)
To train the neural network, we make a uniform sample of the domain of
the function in the region of interest using numpy’s arrange
function.
We then plot the function with matplotlib.
x1, x2 = np.meshgrid(np.arange(-2, 2, 0.01), np.arange(-2, 2, 0.01))
y = peak2d(x1, x2)
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
# Plot the surface.
surf = ax.plot_surface(x1, x2, y, cmap=cm.coolwarm, linewidth=0.01, antialiased=False)
# Add a color bar which maps values to colors.
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()
Approximate the function¶
To fit a model, we need to reshape our data. We concatenate the values
of x1 and x2 in an array X and make y one dimensional.
X = np.concatenate([x1.ravel().reshape(-1, 1), x2.ravel().reshape(-1, 1)], axis=1)
y = y.ravel()
To approximate the function, we use a Pipeline with polynomial
features and a neural-network regressor. We do a relatively small
neural-network.
# Run our regression
layers = [30] * 2
regression = MLPRegressor(hidden_layer_sizes=layers, activation="relu")
pipe = make_pipeline(PolynomialFeatures(), regression)
pipe.fit(X=X, y=y)
To test the accuracy of the approximation, we take a random sample of points, and we print the \(R^2\) value and the maximal error.
X_test = np.random.random((100, 2)) * 4 - 2
r2_score = metrics.r2_score(peak2d(X_test[:, 0], X_test[:, 1]), pipe.predict(X_test))
max_error = metrics.max_error(peak2d(X_test[:, 0], X_test[:, 1]), pipe.predict(X_test))
print(f"R2 error {r2_score}, maximal error {max_error}")
R2 error 0.9998909155392592, maximal error 0.08333217814007243
While the \(R^2\) value is good, the maximal error is quite high. For the purpose of this example we still deem it acceptable. We plot the function.
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
# Plot the surface.
surf = ax.plot_surface(
x1,
x2,
pipe.predict(X).reshape(x1.shape),
cmap=cm.coolwarm,
linewidth=0.01,
antialiased=False,
)
# Add a color bar which maps values to colors.
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()
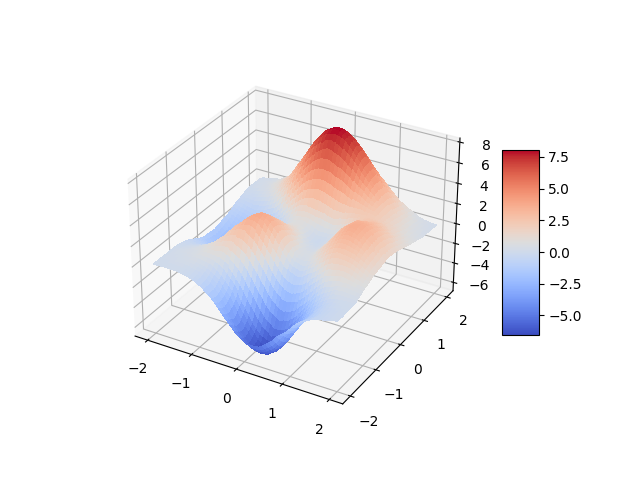
Visually, the approximation looks close enough to the original function.
Build and Solve the Optimization Model¶
We now turn to the optimization model. For this model we want to find
the minimal value of y_approx which is the approximation given by
our pipeline on the interval.
Note that in this simple example, we don’t use matrix variables but regular Gurobi variables instead.
m = gp.Model()
x = m.addVars(2, lb=-2, ub=2, name="x")
y_approx = m.addVar(lb=-GRB.INFINITY, name="y")
m.setObjective(y_approx, gp.GRB.MINIMIZE)
# add "surrogate constraint"
pred_constr = add_predictor_constr(m, pipe, x, y_approx)
pred_constr.print_stats()
Restricted license - for non-production use only - expires 2027-11-29
Warning for adding constraints: zero or small (< 1e-13) coefficients, ignored
Model for pipe:
126 variables
61 constraints
6 quadratic constraints
60 general constraints
Input has shape (1, 2)
Output has shape (1, 1)
Pipeline has 2 steps:
--------------------------------------------------------------------------------
Step Output Shape Variables Constraints
Linear Quadratic General
================================================================================
poly_feat (1, 6) 6 0 6 0
dense (1, 30) 60 30 0 30 (relu)
dense0 (1, 30) 60 30 0 30 (relu)
dense1 (1, 1) 0 1 0 0
--------------------------------------------------------------------------------
Now call optimize. Since we use polynomial features the resulting
model is a non-convex quadratic problem. In Gurobi, we need to set the
parameter NonConvex to 2 to be able to solve it.
m.Params.TimeLimit = 20
m.Params.MIPGap = 0.1
m.Params.NonConvex = 2
m.optimize()
Set parameter TimeLimit to value 20
Set parameter MIPGap to value 0.1
Set parameter NonConvex to value 2
Gurobi Optimizer version 13.0.2 build v13.0.2rc1 (linux64 - "Ubuntu 24.04 LTS")
CPU model: AMD EPYC 7R13 Processor, instruction set [SSE2|AVX|AVX2]
Thread count: 1 physical cores, 2 logical processors, using up to 2 threads
Non-default parameters:
TimeLimit 20
MIPGap 0.1
NonConvex 2
Optimize a model with 61 rows, 129 columns and 1087 nonzeros (Min)
Model fingerprint: 0x31c3dd63
Model has 1 linear objective coefficients
Model has 6 quadratic constraints
Model has 60 simple general constraints
60 MAX
Variable types: 129 continuous, 0 integer (0 binary)
Coefficient statistics:
Matrix range [4e-13, 2e+00]
QMatrix range [1e+00, 1e+00]
QLMatrix range [1e+00, 1e+00]
Objective range [1e+00, 1e+00]
Bounds range [2e+00, 2e+00]
RHS range [3e-02, 8e-01]
QRHS range [1e+00, 1e+00]
Presolve added 74 rows and 11 columns
Presolve time: 0.01s
Presolved: 145 rows, 141 columns, 1226 nonzeros
Presolved model has 3 bilinear constraint(s)
Solving non-convex MIQCP to global optimality
Variable types: 102 continuous, 39 integer (39 binary)
Root relaxation: objective -3.962884e+01, 141 iterations, 0.00 seconds (0.00 work units)
Nodes | Current Node | Objective Bounds | Work
Expl Unexpl | Obj Depth IntInf | Incumbent BestBd Gap | It/Node Time
0 0 -39.62884 0 26 - -39.62884 - - 0s
H 0 0 -4.4712788 -39.62884 786% - 0s
0 0 -32.82103 0 33 -4.47128 -32.82103 634% - 0s
0 0 -32.70683 0 33 -4.47128 -32.70683 631% - 0s
0 0 -31.17002 0 34 -4.47128 -31.17002 597% - 0s
H 0 0 -5.9155571 -31.16536 427% - 0s
0 0 -30.94936 0 32 -5.91556 -30.94936 423% - 0s
0 0 -30.44104 0 35 -5.91556 -30.44104 415% - 0s
0 0 -30.36148 0 34 -5.91556 -30.36148 413% - 0s
0 0 -29.89859 0 35 -5.91556 -29.89859 405% - 0s
0 0 -29.73714 0 37 -5.91556 -29.73714 403% - 0s
0 0 -29.06119 0 39 -5.91556 -29.06119 391% - 0s
H 0 0 -6.4147537 -29.05387 353% - 0s
0 0 -28.79390 0 38 -6.41475 -28.79390 349% - 0s
0 0 -28.21453 0 36 -6.41475 -28.21453 340% - 0s
0 0 -27.77044 0 38 -6.41475 -27.77044 333% - 0s
0 0 -27.52452 0 37 -6.41475 -27.52452 329% - 0s
0 0 -27.45719 0 36 -6.41475 -27.45719 328% - 0s
0 0 -26.93171 0 36 -6.41475 -26.93171 320% - 0s
0 0 -26.80569 0 36 -6.41475 -26.80569 318% - 0s
0 0 -26.72734 0 37 -6.41475 -26.72734 317% - 0s
0 0 -26.65458 0 38 -6.41475 -26.65458 316% - 0s
0 0 -26.56431 0 37 -6.41475 -26.56431 314% - 0s
0 0 -26.52953 0 37 -6.41475 -26.52953 314% - 0s
0 0 -26.35778 0 36 -6.41475 -26.35778 311% - 0s
0 0 -26.30068 0 37 -6.41475 -26.30068 310% - 0s
0 0 -25.60990 0 34 -6.41475 -25.60990 299% - 0s
0 0 -25.52067 0 37 -6.41475 -25.52067 298% - 0s
0 0 -25.33445 0 37 -6.41475 -25.33445 295% - 0s
0 0 -25.17975 0 38 -6.41475 -25.17975 293% - 0s
0 0 -25.05193 0 37 -6.41475 -25.05193 291% - 0s
0 0 -24.99146 0 38 -6.41475 -24.99146 290% - 0s
0 0 -24.89095 0 36 -6.41475 -24.89095 288% - 0s
0 0 -24.84969 0 38 -6.41475 -24.84969 287% - 0s
0 0 -24.79256 0 39 -6.41475 -24.79256 286% - 0s
0 0 -24.77553 0 39 -6.41475 -24.77553 286% - 0s
0 0 -24.65128 0 35 -6.41475 -24.65128 284% - 0s
0 0 -24.61480 0 35 -6.41475 -24.61480 284% - 0s
0 0 -24.55064 0 37 -6.41475 -24.55064 283% - 0s
0 0 -24.52890 0 36 -6.41475 -24.52890 282% - 0s
0 0 -24.51782 0 37 -6.41475 -24.51782 282% - 0s
0 0 -24.51782 0 37 -6.41475 -24.51782 282% - 0s
0 0 -24.51782 0 37 -6.41475 -24.51782 282% - 0s
0 2 -24.51538 0 37 -6.41475 -24.51538 282% - 0s
H 13 13 -6.5579949 -21.94813 235% 43.2 0s
H 103 56 -6.5579949 -18.93640 189% 21.2 0s
H 657 105 -6.5926850 -9.70037 47.1% 22.0 0s
H 974 29 -6.5936644 -7.45151 13.0% 19.7 0s
Cutting planes:
Implied bound: 36
MIR: 110
Flow cover: 40
Relax-and-lift: 2
Explored 1003 nodes (21105 simplex iterations) in 0.86 seconds (0.81 work units)
Thread count was 2 (of 2 available processors)
Solution count 6: -6.59366 -6.59268 -6.55799 ... -4.47128
Optimal solution found (tolerance 1.00e-01)
Best objective -6.593664397686e+00, best bound -7.206287966920e+00, gap 9.2911%
After solving the model, we check the error in the estimate of the Gurobi solution.
print(
"Maximum error in approximating the regression {:.6}".format(
np.max(pred_constr.get_error())
)
)
Maximum error in approximating the regression 7.3519e-11
Finally, we look at the solution and the objective value found.
print(
f"solution point of the approximated problem ({x[0].X:.4}, {x[1].X:.4}), "
+ f"objective value {m.ObjVal}."
)
print(
f"Function value at the solution point {peak2d(x[0].X, x[1].X)} error {abs(peak2d(x[0].X, x[1].X) - m.ObjVal)}."
)
solution point of the approximated problem (0.2388, -1.626), objective value -6.59366439768618.
Function value at the solution point -6.550063792530151 error 0.043600605156029815.
The difference between the function and the approximation at the computed solution point is noticeable, but the point we found is reasonably close to the actual global minimum. Depending on the use case this might be deemed acceptable. Of course, training a larger network should result in a better approximation.
Copyright © 2023-2026 Gurobi Optimization, LLC
Total running time of the script: (0 minutes 8.975 seconds)